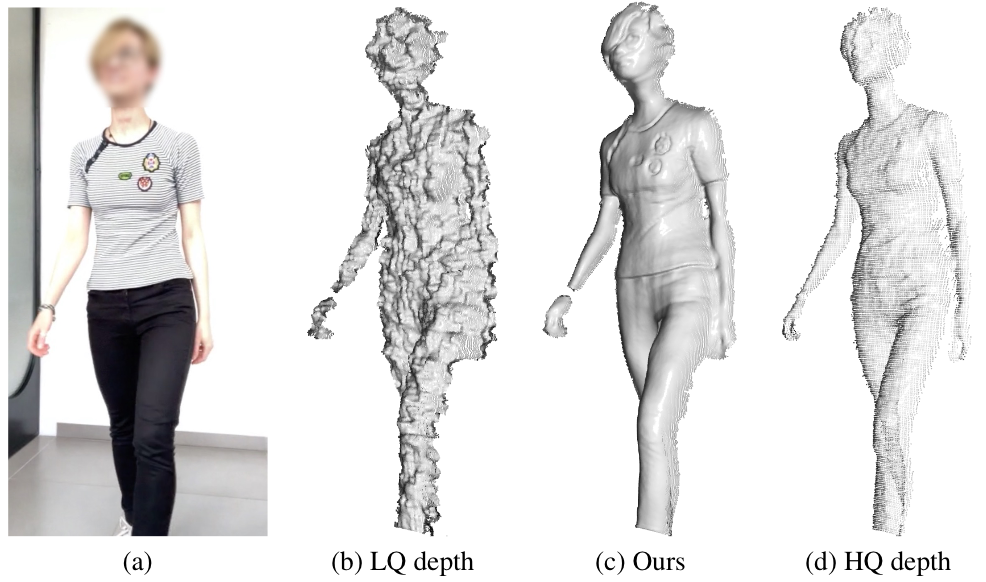
Main Idea
We propose learning-based method for depth denoising of lower-quality (LQ) depth sensor's output using supervision of a higher-quality (HQ) depth sensor. We recorded simultaneous RGB-D sequences with unzynchronized lower- and higher-quality cameras. We consider an in-the-wild scenario where the hardware clock synchronization and prior extrinsic calibration for the sensors is not possible. The created dataset consists of people captured in a variety of poses and lightning conditions using the rig.
We solve a challenging problem of aligning sequences both temporally and spatially:
Temporal Alignment: for each pair of sequences we seek for a shift that would align the timestamps of the two sensors so that a simple nearest neighbour search between the timestamps give us the best mapping.
The correctness of alignment is measured based on spatial alignment score.
Spacial Alignment: for each pair of matched frames we use Superpoint detector to extract a set of 2D correspondences. We then optimize an extrinsic matrix that would transform HQ sensor coordinate system into the LQ one.
To exploit temporal information available in the consecutive frames we use a recurrent model. We utilize two-level training approach based on out-of-fold predictions method. First, we train first-level model to denoise depth on per-frame basis. As a second-level model we train a convolutional recurrent model to account for temporal correlations in the data.
